
データベースクエリが遅いと、アプリケーションのパフォーマンスが静かに低下し、ユーザーをイライラさせ、インフラストラクチャコストが膨らみます。これら5つの実証済みテクニックは、レイテンシのボトルネックを排除し、ユーザーが期待する高速で応答性の高い体験を提供するのに役立ちます。
データベース最適化を簡素化するアプローチの1つは、Adaloで構築することです。Adaloは、データベース駆動型ウェブアプリと、ネイティブiOSおよびAndroidアプリ用のノーコードアプリビルダーで、3つのプラットフォーム全体で1つのバージョンを持ち、Apple App StoreとGoogle Playで公開されています。Adaloの組み込みデータベースはゼロAPIレイテンシを提供し、インフラストラクチャはキャッシングとクエリ最適化を自動的に処理するため、手動でのデータベース調整の代わりにアプリに集中できます。
既存システムを最適化するにせよ、新しいMVPを立ち上げるにせよ、アプリをアプリストアに迅速に配置することで、プッシュ通知とネイティブパフォーマンスで最大のユーザーに到達できます。データベースクエリを非常に高速にする方法は次のとおりです。
データベースクエリレイテンシはアプリケーションのパフォーマンスを低下させ、ユーザーをイライラさせ、コストを増加させる可能性があります。シンプルな内部ツールを構築している場合でも、数千人のユーザーを持つ顧客向けアプリを構築している場合でも、遅いクエリはボトルネックを作成し、システム全体に波及します。これを修正する方法は次のとおりです。
- インデックス作成インデックスを使用して、WHERE句のターゲット列でデータ取得を高速化します。
WHERE,JOINおよびORDER BY句。オーバーインデックスを避けて、書き込み操作の低下を防止します。 - 効率的なクエリを避ける
SELECT *を最適化し、WHERE不要な結合またはサブクエリを最小化するための条件でインデックスを使用します。 - キャッシングメモリを使用して頻繁にアクセスされるデータを保存します Redis または Memcached データベース負荷を削減します。使用します
TTLキャッシュされたデータを最新の状態に保つ。 - パーティショニング大きなテーブルをより小さい部分に分割するか、 プラットフォーム間のデータを同期する (水平または垂直)で、大規模なデータセットのクエリパフォーマンスを向上させます。
- クエリ実行計画実行計画を分析して、順序スキャンやディスクスピルなどのボトルネックを特定します。それに応じてインデックスとクエリ構造を調整します。
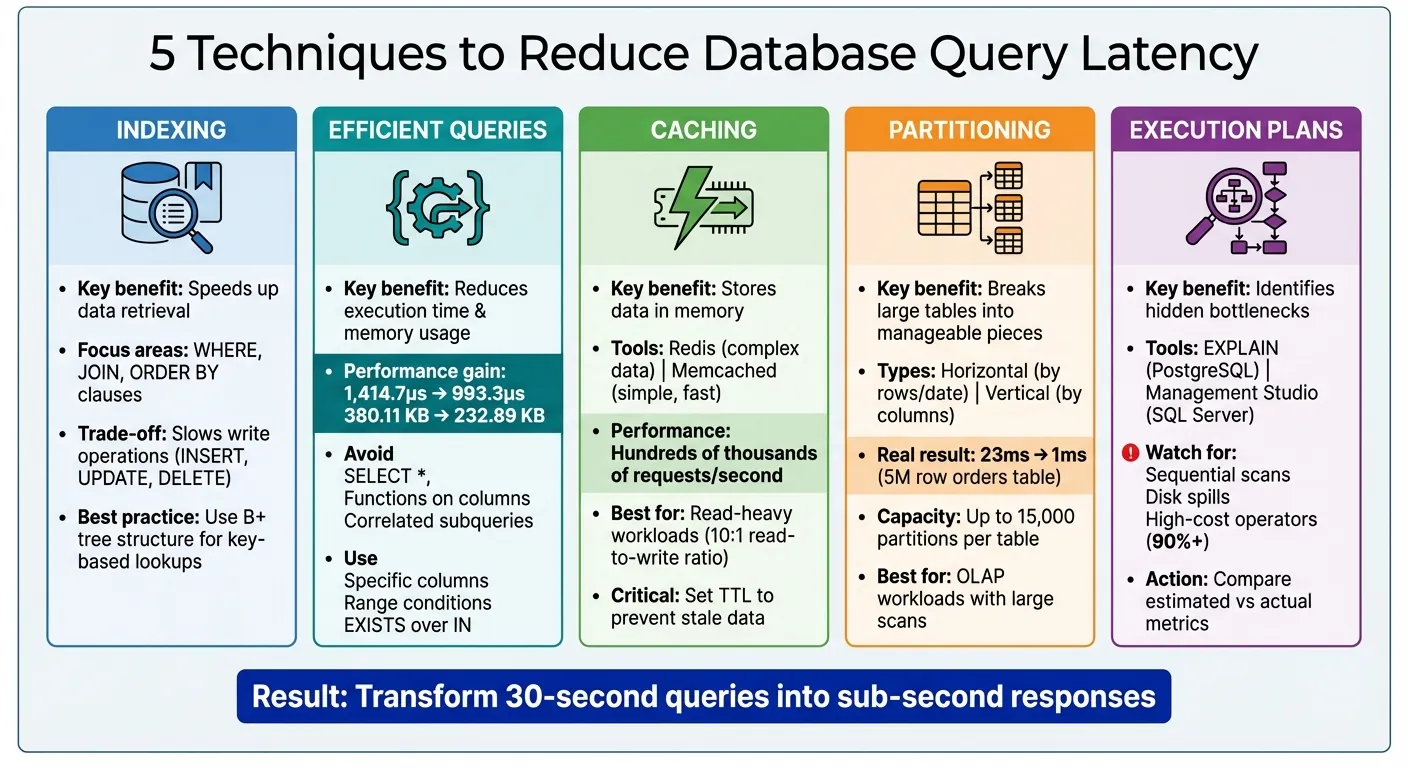
データベースクエリレイテンシの最適化:5つの主要テクニックの比較
データベースクエリが遅く実行されるのはなぜですか? - Next LVL Programming
1.データベースインデックスの使用
データベースインデックスは、本の背にあるインデックスと考えてください。テーブルで必要な行に直接指し示すショートカットとして機能します。これにより、データベースエンジンがすべての行をスキャンする必要がなくなり、データ取得がはるかに高速になります。ほとんどのインデックスは B+ツリー構造に依存しており、これはキーベースの高速検索用に設計されています。適切なインデックスの設定は、データベースクエリを最適化するための重要なステップであり、特に データベース統合オプション を評価する場合に役立ちます
アプリケーション。WHERE句で一般的に使用されている列のインデックス作成に焦点を当てます。これにより、クエリパフォーマンスが顕著に向上します。例えば、 WHERE, JOINおよび ORDER BY カバリングインデックス は必要なすべての列を直接取得できるため、不要な入出力操作を削減します。 より単純なクエリの場合、単一列のインデックスでほとんどの場合対応できます。ただし、複数の条件を持つクエリの場合、
複合インデックス が最適です。複合インデックスを作成する場合、列を戦略的に配置します。等値フィルタで始まり、範囲フィルタに続き、列の相異性を検討してください。 インデックスはSELECT操作を高速化しますが、トレードオフがあります。INSERTやUPDATEなどの書き込み操作を遅くする可能性があります。不要なオーバーヘッドを避けるため、インデックスがどのように使用されているかに注意を払い、価値がないものを削除します。
「一般的な設計ミスは、オプティマイザに選択肢を与えるために多くのインデックスを推測的に作成することです。結果のオーバーインデックスはデータ修正を遅くし、同時実行の問題を引き起こす可能性があります。」- Microsoft SQL Serverインデックス設計ガイド SELECT インデックス作成のベストプラクティス INSERT, UPDATEおよび DELETEインデックスを実装する場合は、次のガイドラインを考慮してください。
主キーは、ほとんどのデータベースシステムで自動的にインデックスされます
結合で使用される外部キーは、インデックス作成から大きな恩恵を受けます
高いカーディナリティを持つ列(多くの一意の値)は、異なる値が少ない列よりもインデックス候補として適しています
- インデックスを定期的に監査して、書き込みオーバーヘッドのみを追加する未使用のものを特定します Adaloは、データベース駆動型ウェブアプリと、ネイティブiOSおよびAndroidアプリ用のノーコードアプリビルダーで、3つのプラットフォーム全体で1つのバージョンを持ち、Apple App StoreとGoogle Playで公開されています。Adaloのような最新のAI搭載アプリビルダーは、この複雑性の多くを自動的に処理します。プラットフォームの2026年インフラストラクチャオーバーホールにより、データベース操作は以前よりも高速に実行され、システムはアプリのニーズに合わせてインフラストラクチャをスケーリングします。つまり、有料プランではレコード制限がありません。これにより、ほとんどの一般的な使用例でインデックスを手動で最適化する必要がなくなります。
- 外部キー 結合で使用される外部キーは、インデックス作成から大きな利益を得られます
- カーディナリティが高い列 (多くの一意な値) は、個別の値が少ない列よりもインデックスの候補として優れています
- 定期的に監査する インデックスを定期的に監査して、書き込みのオーバーヘッドのみを追加する未使用のインデックスを特定します
Adaloは、データベース駆動型のウェブアプリとネイティブiOSおよびAndroidアプリ用のノーコードアプリビルダーです。3つのプラットフォーム全体で1つのバージョンがあり、Apple App StoreおよびGoogle Playに公開されます。Adaloのような最新のAI搭載アプリビルダーは、この複雑さの多くを自動的に処理します。プラットフォームの2026年インフラストラクチャ改造により、データベース操作は以前より実行され、システムはアプリのニーズに合わせてインフラストラクチャをスケーリングします。つまり、有料プランではレコード制限がありません。これにより、ほとんどの一般的な使用例でインデックスを手動で最適化する必要がなくなります。 3~4倍高速 行数や実行時間などの実際のパフォーマンスメトリクスを追加します。これらを比較することで、古い統計情報または最適でないインデックスを示す可能性のある不一致を特定できます。同様に、SQL Serverの管理スタジオの実際の実行計画は、同等の洞察を提供します。これらのツールは、他の最適化手法では明らかにならない可能性のある非効率性を特定するのに役立ちます。
2. より効率的なクエリを作成する
クエリの構造化方法によって、パフォーマンスが大きく左右されます。まず、 SELECT *を避けてください。代わりに、実際に必要な列のみを指定してください。たとえば、 顧客データベース を使用していて、ID、名前、メールアドレスだけが必要な場合は、これら3つのフィールドのみをリクエストしてください。不要な列を取得すると、メモリと帯域幅が無駄になります。
クエリ構造はインデックスと同じくらい重要です。ORM(オブジェクト関係マッピング)で完全なエンティティ取得を使用すると、大きなオーバーヘッドが発生する可能性があります。あるベンチマークによると、ノートラッキングクエリに切り替えると 実行時間が1,414.7マイクロ秒から993.3マイクロ秒に短縮されました メモリ使用量も380.11KBから232.89KBに削減されました。このオーバーヘッドを回避するには、ORM内でプロジェクションを使用してください。 .Select() で EF Core または .values() で Djangoなどのメソッドを使用して、必要なフィールドのみを取得します。
WHERE条件の最適化
WHERE条件を最適化する際は、条件の書き方に注意してください。 WHERE YEAR(hire_date) = 2020などの列の関数は、インデックスが効果的に使用されるのを防ぎます。代わりに、 WHERE hire_date >= '2020-01-01' AND hire_date < '2021-01-01'などの範囲ベースの条件を使用してください。このアプローチは「SARG可能性」(検索引数可能性)を維持し、クエリがインデックスを活用できるようにします。同様に、 LIKE クエリの先頭にワイルドカードがあるパターンを避けてください。これらは完全なテーブルスキャンを強制します。
「クエリが高速に実行されるかどうかの主な決定要因は、適切な場所でインデックスを正しく利用するかどうかです。」
– Microsoftドキュメント
結合とサブクエリの削減
不要な結合とサブクエリの使用を減らしてください。外部クエリに依存する関連サブクエリは特に問題があります。これらは結果セット内の各行に対して1回実行されるためです。代わりに、可能な限り標準結合に置き換えてください。データの存在を確認している場合は、 EXISTS の代わりに INを使用してメッセージング機能を追加することで、クライアントと直接チャットできます。 EXISTS 句を使用してください。この句は一致が見つかるとすぐに処理を停止するため、はるかに効率的です。
データベースの専門家Mike Payneは、「これらのクエリを最適化することは、データベースの速度とスケーラビリティを向上させるために実行できる最も影響力のある単一の取り組みです」と述べています。
AdaloのビルダーであるAdaは、あなたが何を望んでいるかを説明してアプリを生成することができます。Magic Startは説明からアプリの基盤全体を作成し、Magic Addは自然言語を通じて機能を追加します。
SQLを直接記述せずにアプリを構築している場合、Adaloのビジュアルインターフェイスがこれらの最適化を抽象化します。 Magic Add などのプラットフォームのAI支援機能を使用すると、自然言語で必要なデータについて説明でき、システムが効率的なクエリを自動的に生成します。これは、クエリ最適化に深く関わることなくパフォーマンスを望む非技術系ビルダーにとって特に価値があります。
3. よく使用されるクエリをキャッシュする
キャッシングはアプリケーションにメモリブーストを与えるようなものです。データベースに繰り返しクエリする代わりに、頻繁にアクセスされるデータが メモリに保存され、情報の取得に要する時間が削減されます。これにより、ディスクアクセスによる遅延が回避されます。ディスクアクセスは、最善の場合でも2桁のミリ秒かかる可能性があります。
キャッシングに使用される2つの一般的なツールは Redis さらに Memcachedです。Redisは複雑なデータ構造を処理し、ディスク永続化オプションを提供する能力で際立っています。一方、Memcachedはより単純で軽量であり、高速キャッシング専用に設計されています。その力を示すために、単一のインメモリキャッシュノードは 1秒あたり数十万のリクエストを処理できます.
キャッシュアサイドパターン
最も一般的なキャッシング方法は キャッシュアサイド(遅延ロードとも呼ばれます)です。仕組みは次のとおりです。アプリケーションはまずキャッシュをチェックします。データがない場合(「ミス」)、データベースをクエリし、データを取得して、キャッシュを更新します。この方法は、データが書き込まれるより少なくとも10倍多く読み込まれる読み取り集約的なシナリオで特に効果的です。このストラテジーを以前のクエリ最適化技法と組み合わせることで、データベースの負荷を大幅に削減できます。
古いデータが残るのを防ぐため、常にキャッシュされたデータに TTL(存続期間) を設定してください。Redisを使用している場合は、 ハッシュ を使用してデータベース行を保存することを検討してください。このアプローチにより、JSON全体を処理する必要なく、個々のフィールドを更新できます。さらに、 キャッシュヒット率に注意を払ってください。低い比率は、キャッシュが効果的に使用されていないことを意味し、データベース負荷を軽減することなくメモリを無駄にします。
「データベースの速度とスループットは、アプリケーション全体のパフォーマンスに最も影響を与える要因となる可能性があります。」– AWS
キャッシングを実装する時期
すべてのアプリケーションに専用のキャッシングレイヤーが必要なわけではありません。以下の場合、キャッシングの実装を検討してください。
- データベースクエリが最適化にもかかわらず常に遅い
- 同じデータが複数のユーザーによって繰り返しリクエストされている
- アプリケーションがデータベースを圧倒するトラフィックスパイクを経験している
- 読み取り操作が書き込み操作を大幅に上回っている
Adaloのモジュール型インフラストラクチャはプラットフォームレベルでキャッシングを処理するため、プラットフォーム上に構築されたアプリは手動キャッシュ設定なしに最適化されたデータ取得の恩恵を受けます。このシステムは 毎日2000万以上のデータリクエスト 99%以上のアップタイムで処理し、組み込みパフォーマンス最適化の有効性を実証しています。
4. 大規模なデータセットのパーティション分割
テーブルが数百万行に増えると、インデックスが最適に設定されたクエリでさえ遅くなる可能性があります。 パーティショニング 大きなテーブルを小さく管理しやすいピース(パーティション)に分割しながら、単一の論理テーブルとして扱う方法を提供しています。これにより、データベースエンジンは パーティション除外を使用できます。これはクエリ中に関連のないパーティションをスキップし、スキャンする必要があるデータ量を大幅に削減します。重要なのは、効率的なスキャンを保証するためにデータを分割する適切な方法を選択することです。
水平パーティショニング対垂直パーティショニング
データをパーティション化する方法は主に2つあります: 水平パーティショニング さらに 垂直パーティショニング.
- 水平パーティショニング テーブルを行で分割し、多くの場合、日付や地域などの特定の列に基づきます。例えば、売上テーブルを月ごとのチャンクに分割できます。この方法は、時系列データまたは特定の範囲でクエリが頻繁にフィルター処理されるシナリオに特に適しています。
- 垂直パーティショニングは一方、列を分離します。多くのフィールドを持つワイドテーブルに最適です。特に少数の列しか定期的にアクセスされない場合に適しています。例えば、大きなBLOBまたはめったに使用されないフィールドを別のテーブルにオフロードできます。
実際の例を以下に示します。500万行の Airtable データベース の注文テーブルを月ごとにパーティション化すると クエリ時間が23msからわずか1msに短縮されました。SQL Serverなどの最新のデータベースエンジンはテーブルあたり最大15,000個のパーティションを処理できます。ただし、やりすぎないことが重要です。過度なパーティショニング メモリ使用量の増加につながり、クエリが複数のパーティションをスキャンすることになるとパフォーマンスを低下させる可能性があります。
| パーティショニングの種類 | メソッド | 最適用途 |
|---|---|---|
| 水平 | 行を分割(例:日付またはID範囲による) | 範囲ベースのクエリを持つ大規模なデータセット |
| 垂直 | 列を分割(例:BLOBと頻繁にアクセスされるフィールドを分離) | 少数の列しか定期的にクエリされないワイドテーブル |
適切なパーティションキーの選択
パーティショニングを効果的に機能させるには、WHERE句で頻繁に使用される列を選択します。これにより、データベースがパーティション除外を完全に活用できるようになります。さらに、インデックスをパーティショニングスキームに合わせて、メンテナンスタスクを改善します。パーティショニングは、単一行をフェッチするクエリが一般的なOLTPシステムではなく、大規模スキャンを含むOLAPワークロードに特に適しています。
大規模なデータセットを扱うアプリビルダーの場合、Adaloのインフラストラクチャはアプリのニーズに応じてスケーリングします。有料プランではデータベースレコードの上限がありません。適切なデータ関係セットアップにより、プラットフォーム上に構築されたアプリは以下をスケーリングできます 。MVPを小さなオーディエンスで改善している場合でも、本番アプリを数千人のユーザーにスケーリングしている場合でも、コストは一貫しています。無料プランで無制限のテストアプリ(最大500レコード)を構築できますが、公開する準備ができたときだけアップグレードできます。。これにより、レコード制限のある他のプラットフォームが必要とする手動パーティショニング戦略の必要性が排除されます。
5. クエリ実行計画の確認
インデックス作成とクエリリファクタリングに取り組んだ後、実行計画に深く掘り下げることにより、クエリパフォーマンスについてより深い洞察を得ることができます。最適化されたクエリでも予期しないボトルネックに当たる可能性があり、実行計画はデータベースがクエリを処理する方法を明らかにするのに役立ちます。インデックスの使用法、結合方法、ソート操作などの詳細を提供します。
EXPLAINと実行計画ツールの使用
で、Barrettaはまた「刺激が私たちの探求システムを活性化すると、前頭新皮質を活性化し、革新的な戦略とソリューションを考案するよう促します。論理はそれを私たちにさせません。感情がします。刺激的な新しい旅に乗り出すチームは、成功への強い動機付けを感じるだけでなく、より賢く働きます。」 PostgreSQL、などのツールは非常に価値があります。 EXPLAIN さらに EXPLAIN ANALYZE は推定コストを提供しますが、 EXPLAIN は行数と実行時間などの実際のパフォーマンスメトリクスを追加します。これらを比較することで、古い統計または最適でないインデックスを示す可能性のある矛盾を特定できます。同様に、SQL Serverの実行計画管理スタジオは同等の洞察を提供します。これらのツールは、他の最適化手法では明らかではない可能性のある非効率性を特定するのに役立ちます。 EXPLAIN ANALYZE 実際のパフォーマンスメトリクス(行数と実行時間など)を追加します。これらを比較することで、古い統計情報または最適でないインデックスを示す可能性のある不一致を特定できます。同様に、SQL Serverの管理スタジオの実際の実行計画は、同等の洞察を提供します。これらのツールは、他の最適化手法では明らかにならない可能性のある非効率性を特定するのに役立ちます。
注意すべき点
実行計画を分析するときは、大きなテーブルの「Sequential Scan」などのパターンに注意してください。これは多くの場合、インデックスを追加することでパフォーマンスが向上する可能性があることを示唆しています。また、スキャン後にほとんどの行を破棄するフィルター条件を探します。これらは「Index Cond」操作への変換の利点を得ることができるかもしれません。別の危険信号は、ディスクへのスピルをソートまたはハッシュ操作で、クエリレイテンシーを大幅に増加させることができます。CPU時間と経過時間を比較することで、クエリがCPU使用率により制限されているか、I/O操作を待機しているかを判断することもできます。
「Sort」または「Hash Join」などの単一のオペレータが クエリコストの90%を占める場合、最適化の明確なターゲットです。プランナーオプションを一時的に無効にして、別の結合戦略をテストし、実際のパフォーマンスが向上するかどうかを確認することもできます。暗黙的なデータ型変換に関する警告に注意してください。これらは各行を個別に処理するようエンジンに強制する可能性があり、インデックス効率を損なわせます。
自動パフォーマンス分析
手動で実行計画を分析することを好まない人のために、Adaloは X-Rayを提供しています。これはユーザーに影響を与える前にパフォーマンスの問題を特定するAI機能です。このプロアクティブなパフォーマンス監視アプローチにより、データベースの内部に深く掘り下げることなくボトルネックをキャッチして修正できます。この機能は潜在的なスケーラビリティの懸念を強調し、最適化を提案し、非技術的なビルダーのアプリケーションをスケーリングする場合に特に価値があります。
アプリビルダーのためのデータベースアプローチの比較
アプリビルディングプラットフォームを選択する場合、データベースのパフォーマンスとスケーラビリティが主要な考慮事項である必要があります。異なるプラットフォームはデータストレージとクエリの最適化を根本的に異なる方法で処理します。
| プラットフォーム | データベースアプローチ | レコード制限 | 初期価格 |
|---|---|---|---|
| Adalo | ビルトイン+外部接続 | 有料プランで無制限 | 月額36ドル |
| Bubble | ワークロードユニット付きビルトイン | ワークロード計算による制限 | $69/月 |
| Glide | スプレッドシートベース | 制限付き、追加料金が適用されます | 月額60ドル |
| FlutterFlow | 外部のみ(ユーザー管理) | 外部プロバイダーに依存 | 月額$70 + データベースコスト |
Bubbleはより多くのカスタマイズオプションを提供していますが、その柔軟性により、負荷の増加下でパフォーマンスが低下するアプリケーションが生まれることが多くあります。多くのBubbleユーザーは結局、アプリを最適化するために専門家を雇うことになります。数百万のMAUの主張は通常、専門家の支援を得た場合にのみ実現可能です。Bubbleのモバイルアプリソリューションはウェブアプリのラッパーでもあり、スケール時に潜在的な課題をもたらします。
FlutterFlowは技術的には「ノーコード」ではなく「ロウコード」であり、技術的ユーザーを対象としています。ユーザーは自分の外部データベースをセットアップして管理する必要があり、これには重大な学習の複雑性が必要です。最適なセットアップに満たないものはスケール問題を生じさせる可能性があり、そのためFlutterFlowエコシステムは有料の専門家が豊富です。
Glideはスプレッドシートベースのアプリで優れていますが、汎用的でシンプルなアプリを作成し、創造的な自由度が限定されています。Apple App StoreやGoogle Play Storeへの公開をサポートしていないため、配布オプションが限定されています。
結論
データベースクエリのレイテンシーを削減することは、速度を向上させ、スケーラビリティを確保することについてです。インデックス作成、効率的なクエリの記述、キャッシング、パーティショニング、実行計画の確認などの手法により、遅い30秒クエリを高速な1秒以下の応答に変えることができます。
しかし、利点は単なる速度を超えています。合理化されたクエリは消費されるサーバーリソースが少なくなるため、月額コストを削減でき、ユーザーベースの成長に伴ってスムーズな体験を確保できます。効率的なクエリはサーバーの負荷を軽減し、1秒あたり5リクエストなどのAPIレート制限に達することを回避するのにも役立ちます。 Airtableの1秒あたり5リクエストの制限。今の小さな調整により、後で大きな問題を防ぐことができます。
AIを活用したアプリビルダーであるAdaloは、ビジュアルインターフェースと統合されたバックエンドを通じてこれらの最適化を簡素化します。より小さなデータセットを持つアプリの場合、Adaloの組み込みデータベースはAPIレイテンシーゼロで高速なパフォーマンスを提供します。スケールする必要があるか、共同で作業する必要があります。月額$36から開始するプロフェッショナルプランで利用可能な外部コレクションを使用して、Airtable、PostgreSQL、MS SQL Serverなどの外部データベースに接続できます。この柔軟性により、シンプルなセットアップで始めて、アプリを一新することなく必要に応じてスケールできます。
開始するには、次のようなツールを使用して最も遅いクエリをプロファイリングすることに焦点を当ててください EXPLAIN 、最も差し迫ったボトルネックに取り組みます。インデックスを追加するか、キャッシング層をセットアップするかどうかに関わらず、すべての改善は最後に構築されます。マイク・ペインから Paessler は賢明に述べています:
「最適化できないものは見えません。データベース監視は、パフォーマンスの問題が正確にどこに存在するかを明らかにします。」
トラブルスポットを特定したら、修正は多くの場合簡単で、即座の結果をもたらします。
関連ブログ記事
- ノーコードアプリのパフォーマンスを最適化する8つの方法
- IBM DB2データを使用するアプリを作成する方法
- ノーコードアプリのパフォーマンスを追跡する5つのメトリクス
- 大規模データセット向けのノーコードアプリのスケーリング
Adaloを他のアプリ構築ソリューションより選ぶ理由は何ですか?
Adaloは、単一のコードベースから真のネイティブiOSおよびAndroidアプリを作成するAI搭載アプリビルダーです。Webラッパーと異なり、ネイティブコードにコンパイルされ、Apple App StoreおよびGoogle Play Storeに直接公開されます。有料プランで無制限のデータベースレコードがあり、使用量ベースの料金がないため、予測可能な価格設定で請求ショックを回避できます——アプリの起動で最も難しい部分が自動的に処理されます。
Adaloは、真のネイティブ iOS および Android アプリを作成する AI 駆動型アプリ ビルダーです。Webラッパーとは異なり、ネイティブコードにコンパイルされ、単一のコードベースからApple App StoreおよびGoogle Play Storeに直接公開されます。アプリの起動の最も難しい部分は自動的に処理されます。
AdaloのドラッグアンドドロップインターフェイスとAIアシスト構築により、数ヶ月ではなく数日でアイデアから公開アプリまでたどり着くことができます。Magic Startはシンプルな説明から完全なアプリ基盤を生成し、プラットフォームは複雑なApp Store送信プロセスを処理するため、証明書とプロビジョニングプロファイルではなく、機能とユーザーエクスペリエンスに集中できます。
Adaloのドラッグアンドドロップインターフェースと、Magic StartとMagic Addを通じたAI支援ビルディングにより、数週間ではなく数時間で完全なアプリを作成できます。プラットフォームはApp Store全体の提出プロセスを処理し、通常アプリの立ち上げを遅くする技術的な障壁を取り除きます。
アプリのデータベースクエリを簡単に最適化できますか?
はい、Adaloのビジュアルインターフェースと統合されたバックエンドにより、SQLを記述することなくデータベースパフォーマンスを最適化できます。より小さなデータセットを持つアプリの場合、Adaloの組み込みデータベースはAPIレイテンシーゼロを提供し、外部コレクションを使用してより大きなデータセット用のPostgreSQLやAirtableなどの外部データベースに接続できます。
データベースクエリのレイテンシーを削減する最も影響力のある方法は何ですか?
適切なデータベースインデックス作成は多くの場合最も影響力のある最初のステップです。インデックスはテーブル全体をスキャンする代わりに必要な行に直接ポイントするショートカットとして機能します。WHERE、JOIN、ORDER BY句で一般的に使用されるカラムのインデックス作成に焦点を当てて、最高のパフォーマンスゲインを得てください。
大規模なデータセットにはキャッシングとパーティショニングのどちらを使用するべきですか?
頻繁にアクセスされ、頻繁に変わらないデータがある場合はキャッシングを使用してください。RedisやMemcachedなどのツールは1秒あたり数十万のリクエストを処理できます。テーブルが数百万行に成長し、クエリが日付などの特定の範囲でフィルタリングする場合はパーティショニングを使用してください。データベースは無関係なデータを完全にスキップできます。
パフォーマンスの問題を引き起こしているクエリをどのように特定しますか?
PostgreSQLのEXPLAINやSQL Serverの実際の実行計画などのクエリ実行計画ツールを使用して、データベースがクエリをどのように処理するかを正確に確認してください。Adaloはまた、ユーザーに影響を与える前にパフォーマンスの問題を特定するAI機能であるX-Rayを提供しています。
データベースクエリでSELECT *を使用しないのはなぜですか?
SELECT *を使用するとテーブルからすべてのカラムを取得し、特定のフィールドのみが必要な場合にメモリと帯域幅を浪費します。必要なカラムのみを指定することで、実行時間とメモリ使用量を大幅に削減できます。ベンチマークは、対象的なクエリへの切り替えでメモリ消費をほぼ40%削減できることを示しています。
Adalo と Bubble のどちらがより手頃ですか?
Adaloは月額$36から開始し、無制限の使用量と有料プランでレコード上限なし。Bubbleは月額$69から開始し、使用量ベースのワークロードユニット料金とレコード制限があります。Adaloはまた、公開後の無制限のアプリ更新を含む一方、Bubbleは再公開の制限があります。
Adaloはモバイルアプリ開発でFlutterFlowより優れていますか?
非技術ユーザーの場合、はい。FlutterFlowは「ロウコード」で技術的ユーザーを対象としており、独自の外部データベースをセットアップして管理する必要があります。Adaloは統合データベースを含み、有料プランでレコード上限なしで、そのビジュアルビルダーは「PowerPointのように簡単」と説明されていますが、ネイティブiOSおよびAndroidアプリを生成しています。
Adalo にはデータベースレコード制限がありますか?
いいえ。有料プランは上限なしの無制限のデータベースレコードです。正しいデータ関係のセットアップにより、Adaloアプリは月間100万人以上のアクティブユーザーをスケールできます。プラットフォームのモジュール型インフラストラクチャは、アプリのニーズに自動的にスケールします。
大家向けトップ7アプリ | 2026年版

レガシーデータベースによるAPI応答時間の改善
クエリーチューニング、インデックス、キャッシング、コネクションプーリング、およびN+1クエリーの修正を使用して、レガシーデータベースを使用するAPIを高速化し、レイテンシーを削減します。

レガシーAPIのパフォーマンス問題を解決する
キャッシング、クエリーチューニング、APIラッパー、および段階的なマイクロサービスマイグレーションでレガシーAPIのレイテンシーを削減する――実用的なクイックウィンと長期的な

AIとマイクロアプリが企業ワークフローを変える方法
AI駆動マイクロアプリは反復的なタスクを自動化し、レガシーシステムを現代化し、ノー・コードアプリビルドを有効にしてワークフローを加速し、コストを削減し、

SaaSの未来:AI駆動ワークフロー自動化
AI優先SaaSは自律型エージェント、自然言語ワークフロー、予測的最適化を使用して、プロセスを加速し、コストを削減し、統合を行います