
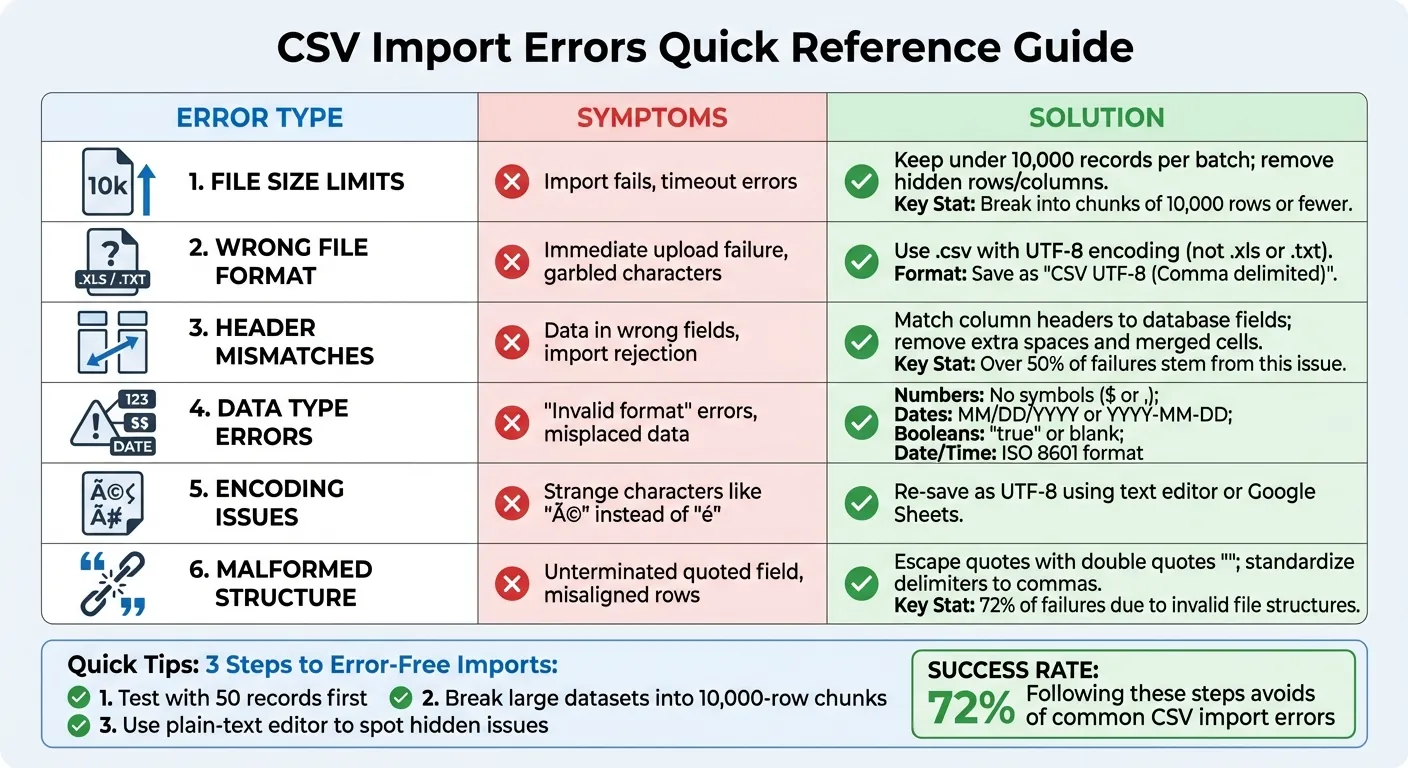
CSVインポートは大規模なデータセットを管理するための救世主ですが、単純なエラーが原因で失敗することがよくあります。最も一般的な問題を回避するために知っておくべきことは次のとおりです。
- ファイルサイズの制限: ファイルは10,000レコード以下に保つと、スムーズなインポートが実現します。空の行または列に隠れたデータはファイルサイズを増やす可能性があるため、アップロード前にファイルをクリーンアップしてください。
- 間違ったファイル形式:
.csv: ファイルは UTF-8エンコーディングで保存します。次のような形式は適切に変換しない限り失敗します。.xlsまたは.txtヘッダーと列の不一致 - : 列ヘッダーがデータベースフィールドと一致することを確認してください。余分なスペース、結合されたセル、またはヘッダーの欠落がエラーの原因となる可能性があります。データ型エラー
- : 数値にはやコンマなどの記号を含めてはいけません。日付は
$などの形式に従う必要があり、ブール値は「true」または空白である必要があります。MM/DD/YYYYエンコーディングの問題 - : 文字化け(例:「é」)はエンコーディングの問題を示しています。ファイルをUTF-8として保存するか、Google Sheetsなどのツールを使用して再度エクスポートしてください。クイックヒント:
完全なアップロードの前に50レコードでテストしてください。
- 大規模なデータセットを10,000行以下の小さなチャンクに分割してください。
- プレーンテキストエディタを使用して、エスケープされていないクォートや混合区切り文字などの隠れた問題を見つけてください。
- これらの手順に従うことで、CSVインポートエラーの72%を回避し、手間のかからないアップロードプロセスを実現できます。
CSVインポートエラーと修正方法 - クイックリファレンスガイド
ファイルサイズおよび形式の問題
ファイルサイズが制限を超える
CSVインポートは、データベース駆動型のWebアプリとネイティブiOSおよびAndroidアプリ用のノーコードアプリビルダーであるAdaloで大規模なデータセットを管理するための救世主です。すべての3つのプラットフォーム全体で1つのバージョンで、Apple App StoreとGoogle Playに公開されています。最も一般的な問題を回避するために知っておくべきことは次のとおりです。
ファイルサイズが膨らむ一般的な原因の1つは、隠された「ゴースト」データ―見かけ上は空の行または列であっても、ファイル内のスペースを占める―です。これらが適切にクリーンアップされない場合、解析エラーが発生する可能性があります。
データセットが10,000レコードを超える場合、サーバー側の変換に依存するのではなく、ExcelファイルをCSVに手動で変換する方が良好です。サーバー側の変換は遅くなる可能性があり、エラーが発生しやすくなります。さらに、Adaloのデータベースマッパーにより、不要なCSV列に対して「なし」を選択して、処理の負担を軽減できます。
Adaloなどのプラットフォームで作業する場合、ファイルは
間違ったファイル形式
拡張子を持ち、 .csv を使用する必要があります。 UTF-8エンコーディングなどの形式のファイルを最初に変換しないでアップロードすると、即座に失敗します。文字化け―しばしば「宇宙人の象形文字」と呼ばれる―に気付いた場合、ファイルが間違ったエンコーディングで保存されていることを示しています。 .txt または .xls/.xlsx ファイルを正しい形式で保存するには:
Microsoft Excel(2016以降)
- : 「ファイル」>「名前を付けて保存」 」に移動して、ドロップダウンメニューから「CSV UTF-8(カンマ区切り)(*.csv)」を選択してください。 メニューから選択します Google Sheets : 「
- Google Sheetsファイル」>「ダウンロード」>「カンマ区切り値(.csv)」 をクリックして、UTF-8エンコーディングを確認してください。 エンコーディングがまだ正しくない場合は、
- メモ帳 またはTextEditなどのプレーンテキストエディタでファイルを開き、「名前を付けて保存」を選択して、「 「CSVやExcelスプレッドシートなどのデータファイルをインポートするのは、心臓の弱い人向けではありません。データインポートプロセスでは、多くのことがうまくいかない可能性がありますが、幸いなことに、これらの一般的なエラーは簡単に修正できます。」―Anne Bonner、ライター、Flatfile 次に、データ構造とマッピングの問題がCSVインポートをさらに複雑にする方法について詳しく説明します。データ構造とマッピングの問題 UTF-8エンコーディング.
「CSVやExcelスプレッドシートなどのデータファイルをインポートするのは、気が弱い人向けではありません。データインポートプロセスでは多くの問題が発生する可能性がありますが、幸いなことに、これらの一般的なエラーは簡単に修正できます。」– Anne Bonner、ライター、Flatfile
次に、データ構造とマッピングの問題がCSVインポートをさらに複雑にする方法について詳しく説明します。
データ構造とマッピングの問題
列とヘッダーの不一致
CSVアップロードは難しい場合があります。特にファイルのヘッダーがデータベース構造と一致していない場合です。実際、 セルフサービスのCSVアップロード失敗の50%以上は この問題に起因しています。よくある原因は何でしょうか? ヘッダー行の欠落, 列名の余分なスペースまたは マージされたセル Excelの書式設定から残っているもの。UTF-8ファイルのバイト順マーク(BOM)さえも、最初の列名を混乱させ、インポートを失敗させる可能性があります。
Adaloは、CSVの列をデータベースフィールドに自動的にマッチングすることでこのプロセスを簡素化します。ただし、正確な名前の一致に限定されません。インポート中に、ドロップダウンメニューを使用してCSVの列をデータベースフィールドに手動で割り当てることができます。たとえば、CSVに「Customer Name」というタイトルの列がありますが、データベースではそれを「Full Name」と呼んでいる場合は、簡単にそれらをペアリングできます。列を使用していませんか?「None」を選択してスキップしてください。マッピングを再度確認してエラーを避けてください。
リレーションシップフィールド は特別な注意が必要です。一対多のリレーションシップの場合、CSVの値は 完全に一致する必要があります 関連レコードの「最初のプロパティ」(ラベルフィールド)と。たとえば、注文を顧客にリンクしており、顧客コレクションの「最初のプロパティ」が「Email」の場合、CSVには正確なメールアドレスを含める必要があります。顧客IDや名前ではなく。
簡単にするために、AdaloデータベースビューからサンプルCSVをダウンロードしてください。これにより、データを正しくフォーマットするための明確なテンプレートが得られます。ヘッダーが一致したら、フィールドマッピングを再度確認して、さらなる問題を防いでください。
フィールドマッピングの問題
マッピングエラーはデータを誤配置することができます。たとえば、テキストを数値フィールドに入れたり、必須フィールドを空のままにしたりします。 失敗の約72%は 無効なファイル構造が原因です。
Adaloの各プロパティタイプには特定のフォーマット要件があります:
- 数字: シンボルは許可されていません。
- ブール値: 「true」を使用するか、空のままにしてください。
- 日付: MM/DD/YYYYまたはYYYY-MM-DD形式に従ってください。
- 日付と時間: ISO 8601形式を使用してください(例:2022-07-04T02:00:00Z)。
- 場所: 完全なカンマ区切りアドレスを入力してください。
「CSVは実際には標準化されたフォーマットではありません...ファイルがインポートツールが期待していたものから少し「ずれている」可能性は常にあります。」– CSVローダー
大規模なデータセットの場合、CSVを次の方法で分割してください 10,000行以下の小さなチャンク。大規模なインポート(100,000レコードなど)は、処理に数時間かかる場合があります(1つの例では約 わずか3時間かかりました)。フィールドをフォーマットしてマッピングするのに時間をかければ、頭痛の種を避けることができ、Adaloのツールを使用したスムーズなCSVインポートを確保できます。
データ型とコンテンツの問題
一貫性のないデータ型
CSVファイルは情報をプレーンテキストとして保存します。これにより、特定のフィールドに一致しないデータ型が現れると、変換エラーが発生する可能性があります。たとえば、テキストが数値またはブール値フィールドに入る場合、インポートプロセスは失敗します。一般的な原因には、フォーマットシンボルが含まれます。価格のドル記号、大きな数字のコンマ、電話番号のダッシュなど。Adaloの 数値 プロパティは、整数、小数、または負の値のみを受け入れ、シンボルまたは文字は厳密に除外します。
日付フィールドも同じくらい厳密です。「07/31/2020」または「2020-07-31」の代わりに「July 31st 2020」と書くと、パーサーが失敗します。日付と時刻フィールドの場合、ISO 8601形式に従ってください。例えば: 2022-07-04T02:00:00Z.
隠れたスペースも悪影響を及ぼす可能性があります。たとえば、「John」に見える隅は、実際には「 John 」という見えないスペースを含んでいる可能性があり、リレーションシップマッチの失敗につながります。地域別のフォーマット違いはさらに別の困難を加えます。使用中 1.234,56 の代わりに 1,234.56 小数の場合は、米国式の数値形式を期待するシステムを混乱させることができます。
これらの問題を回避するには、アップロード前にデータをクリーンアップしてください:
- 列から非数値文字と余分なスペースを削除します。
- ブール値フィールドには「true」のみを使用するか、セルを空のままにしてください。
- すべての日付を標準化する MM/DD/YYYY または YYYY-MM-DD.
一致しないデータ型を超えて、不完全または無効な値もCSVインポートを中断する可能性があります。
欠落または無効なデータ
必須列の空のフィールドは「Missing required field」エラーをトリガーし、インポートを停止します。問題がすぐに明らかではない場合もあります。データは完全に見える場合がありますが、予想形式と一致しない無効な値を含んでいる可能性があります。
これらのエラーを検出するには、メモ帳やTextEditなどのプレーンテキストエディタでCSVを開きます。Excelなどのスプレッドシートソフトウェアとは異なり、テキストエディタは生データを表示し、一貫性のない区切り文字、引用符を閉じていない、または奇妙な文字(「é」またはランダムボックスなど)などの隠れた問題を明らかにします。これらは多くの場合、インポート前に修正が必要なエンコーディングの問題から生じます。
Adaloを含む最新のインポートツールは、リアルタイムエラーフィードバックを提供します。「Invalid date format」または「Expected a number」などのメッセージを含む問題のあるセルをハイライトし、問題を特定して解決しやすくします。Adaloのインポートツールは正確なデータ入力を要求するため、標準化されたフォーマットと完全なフィールドが不可欠です。リレーションシップフィールドの場合、CSVの値は 完全に一致する必要があります 関連レコードの「最初のプロパティ」と。大文字小文字の区別や余分なスペースなどのささいな詳細でさえエラーを引き起こす可能性があります。
データがインポート用に準備されていることを確認するには:
- ターゲットシステムで提供されたテンプレートを使用して、列の順序とデータ型を正しく揃えます。
- 大規模なデータセットの場合は、10,000件以下のバッチでインポートしてください。このアプローチはエラーを分離し、システムタイムアウトを回避します。
- ファイルの最後にある空白行を削除して、「空の列」エラーを防ぎます。
| プロパティタイプ | Adalo CSVインポートの必須形式 | 回避すべき一般的なエラー |
|---|---|---|
| 数値 | 整数、小数、または負の数のみ | 通貨記号または文字を含める |
| 真偽値 | 「true」またはfalseの場合は[空白] | 「Yes/No」または「1/0」を使用する |
| 日付 | MM/DD/YYYYまたはYYYY-MM-DD | 同じ列内での形式が一貫していない |
| 日付と時刻 | ISO 8601(例:2022-07-04T02:00:00Z) | UTCオフセットのないローカル時刻文字列を使用する |
| 場所 | フルカンマ区切り:番地、市区町村、都道府県、郵便番号、国 | 郵便番号や国などの必須コンポーネントが欠落している |
エンコーディングと解析の失敗
間違ったエンコーディング
CSVファイルが「é」の代わりに「é」のような奇妙な文字を表示している場合、エンコーディングの問題の可能性があります。これは、最新のシステムの標準であるUTF-8の代わりに、ASCIIやWindows-1252などの古いエンコーディング形式が使用されている場合に発生します。
「特殊文字が欠落している場合、またはテキスト/文字が宇宙人の象形文字のように見える場合、これはほぼ常にエンコーディングの問題です。」- CSVローダー
これを修正するには、Notepad(Windows)またはTextEdit(Mac)などのテキストエディタでファイルを開き、「別名で保存」を選択して、エンコーディング形式としてUTF-8を選択します。Microsoft Excel 2016以降を使用している場合は、ファイルを「CSV UTF-8(カンマ区切り)」として保存します。別の簡単な方法は、ファイルをGoogle Sheetsにアップロードしてから、CSVとして再度ダウンロードすることで、自動的にUTF-8エンコーディングが適用されます。
UTF-8 BOM(バイト順序マーク)により、最初の列ヘッダーが正しく表示されない場合があります。これに対処するには、高度なテキストエディタを使用してファイルを「UTF-8(BOMなし)」として保存してください。
不正なCSV構造
適切なエンコーディングであっても、CSVファイルの構造エラーは問題を引き起こす可能性があります。一般的な問題の1つは、エスケープされていない引用符です。例えば、セルに次のようなテキストが含まれている場合 This has a "quote" insideパーサーは内部の引用符をフィールドの終了と誤解釈し、データの位置ずれまたは「終了していない引用フィールド」エラーが発生する可能性があります。これを解決するには、セル内の引用符を2倍にしてください。 This has a ""quote"" inside.
混合区切り文字は別の一般的な原因です。行によってカンマを使用する行とセミコロンを使用する行がある場合、ファイルが正しくインポートされない可能性があります。テキストエディタの「検索と置換」機能を使用して、すべての区切り文字をカンマに統一してください。同様に、改行が一貫していることを確認してください( または \r).
業界研究によると、CSVインポート失敗の72%は、適切な検証で回避できる無効なファイル構造が原因です。ファイルをプレーンテキストエディタで表示すると、スプレッドシートソフトウェアが隠すかもしれない一貫性のない改行、引用符なしのタブ、余分なカンマなどの隠れた問題を見つけるのに役立ちます。クイックフィックスとしては、ファイルをExcelにインポートして「CSV UTF-8」として再度保存すると、多くの場合、引用符のエスケープが修正され、改行が正規化されます。
| 問題タイプ | 症状 | 解決方法 |
|---|---|---|
| 間違ったエンコーディング | 文字化け(例:「é」、予期しない記号) | テキストエディタまたはExcelを使用してUTF-8として再度保存する |
| BOM問題 | 最初の列ヘッダーが誤読または奇妙な文字 | 「UTF-8(BOMなし)」として保存する |
| エスケープされていない引用符 | データの位置ずれ;「終了していない引用フィールド」エラー | 置換 " なし "" セル内で |
| 混合区切り文字 | 行全体でのデータの位置ずれ | すべての区切り文字をカンマに統一する |
| 改行 | 行のマージまたは不正な行数 | 改行を正規化する \r |
AdaloでエラーのないCSVインポートのベストプラクティス Adalo
インポート前にデータをプレビューして検証する
一般的なCSVインポートエラーを回避するために、Adaloにアップロードする前にデータを検証することが重要です。まずプレーンテキストエディタでCSVファイルを開いてください。これにより、エスケープされていない引用符、混合区切り文字、または一貫性のない改行などの潜在的な問題の可因を見つけることができます。ご存知ですか、 CSVインポート失敗の72%は無効なファイル構造に由来しています?ここでクイックチェックを実施すれば、後で多くの手間を省くことができます。
50件のレコードだけでインポートをテストすることから始めてください。これにより、大規模なアップロードに進む前に、フォーマットとマッピングが正しいことを確認できます。また、データをクリーンアップしてください。空の行または列を削除してください。
データがAdaloのフォーマットルールに従っていることを確認してください。例えば、以下のようにしてください:
- 数字数字、小数点、またはマイナス記号に限定してください。ドル記号やコンマは使用しないでください。
- 日付次のような形式を使用してください: MM/DD/YYYY または YYYY-MM-DD.
- 日付と時間ISO 8601形式に従ってください。例えば、以下のようにしてください: 2022-07-04T02:00:00Z.
- 真偽値フィールド「」という単語を使用してください:真の真の値の場合;偽の場合はセルを空のままにしてください。
- 位置情報フィールド完全な形式を含めてください。番地、市区町村、都道府県、郵便番号、国です。
データの準備ができたら、Adaloのマッピングツールがそれをデータベース構造と調整するのに役立ちます。
データベースマッピングにAdaloツールを使用してください
Adaloのマッピングツールは、CSVの列をデータベースプロパティに自動的にマッチングすることで、インポートプロセスを簡素化します。自動ペアリングが正確でない場合は、ドロップダウンメニューを使用して正しい列を手動で選択できます。「なし」を選択することで、不要な列を除外することもできます。CSVの列名がAdaloのプロパティ名または順序と一致していなくても問題ありません。一致する必要はありません。
リレーションシップフィールド(一対多)の場合、CSVの値は 「最初のプロパティ」 (ラベルフィールド)と完全に一致する必要があります。マッピング問題が発生した場合は、この最初のプロパティがテキストフィールドまたは数値フィールドであることを二重確認し、CSVの値が完全に一致していることを確認してください。Adaloのインポーターは既存のレコードを上書きするのではなく、新しいレコードを追加することに注意してください。そのため、現在のデータは安全です。
データとマッピングが正しく設定されている場合、大規模なインポートでもスムーズに実行できます。
使用 と連携して、MS SQL ServerやPostgreSQLなどのエンタープライズデータベースに接続します。 複雑な統合の場合
AdaloのネイティブCSVインポーターはほとんどの標準インポートに適していますが、10,000件を超えるレコードを扱う場合、またはより多くの処理能力が必要な場合、 と連携して、MS SQL ServerやPostgreSQLなどのエンタープライズデータベースに接続します。 があなたの頼りになるツールです。このプラットフォームは、複雑または大規模なインポートを管理する場合に特に役立ち、APIのない従来のシステムやレガシーデータベースなど、AdaloをERPなどの外部システムに接続することができます。
を使用するチームの場合、 Adalo BlueDreamFactoryは非常に価値があります。CSVファイルを常にエクスポートおよびインポートする手間をかけずに、シームレスなデータ統合を実現します。代わりに、MS SQL ServerやPostgreSQLなどのデータベースに直接接続し、Adaloアプリを送信元データと同期に保ちます。ただし、大規模なデータセット(例えば100,000件のレコード)の処理には、列の複雑さに応じて最大3時間かかる場合があります。DreamFactoryを使用すれば、これらのインポートを効率的に計画し、実行することができ、最も困難なデータ移行さえも管理可能になります。
.csvファイルをインポートする(日付形式を変更してエラーを回避する)
結論
AdaloへのCSVファイルのインポートは面倒である必要はありません。CSVインポート障害の72%が無効なファイル構造が原因であることをご存知ですか?これを回避するには、Adaloが必要とすることを知ることが重要です。ファイルはUTF-8エンコーディングを使用する必要があり、ヘッダーはAdaloのフォーマットルールと一致する必要があり、データは特定のガイドラインに従う必要があります。例えば、シンボルなしの数値、MM/DD/YYYYまたはYYYY-MM-DD形式の日付、および「true」として、または空白として表示される真偽値です。
インポート時に、データのマッピングに細心の注意を払ってください。リレーションシップフィールドは関連するコレクションの最初のプロパティと完全に一致する必要があります。Adaloでのポイントは、CSVインポートは新しいレコードを追加するように設計されています。大規模なデータセットの場合は、インポートを10,000件以下のバッチに分割してください。データセットが10,000件を超える場合、または外部データベースに接続する必要がある場合は、DreamFactoryなどのツールが役立ちます。ただし、DreamFactoryを使用した大規模なインポート(100,000件のレコード)の処理には最大3時間かかる場合があります。これにより、大規模なインポートのステージングと計画がさらに重要になります。
小さく始めてください。初期バッチの50件のレコードでセットアップをテストしてください。プレーンテキストエディターを使用してCSVファイルを検証し、Adaloのマッピングツールに依存して、すべてが一致していることを確認してください。小規模なインポート用の無料プランで作業する場合でも、大規模なインポート用の有料プランで作業する場合でも、これらの手順に従うことで、時間と手間を節約できます。正確なデータ、適切なフォーマット、スマートなバッチ処理を使用すれば、CSVインポートをシームレスで予測可能なプロセスに変えることができます。
関連ブログ記事
- Google Sheetsを実際のデータベースとして使用してアプリを作成する方法?
- Excelデータをアプリに変える方法は?
- ノーコードアプリのためのリアルタイムデータ同期
- Airtable対Google Sheets:MVP データの比較
よくある質問
インポート用にCSVファイルを適切にフォーマットするために、どのような手順を実行する必要がありますか?
スムーズなインポート用にCSVファイルを準備するには、以下をしてください: ヘッダー行 を含める開始し、各列を明確にラベルしてください。各フィールドはコンマで区切る必要があり、各列内のデータは一貫した形式に従う必要があります。
一般的な落とし穴を回避するには、コンマ、引用符、または改行を含むテキストを二重引用符で囲みます。また、ファイルがUTF-8エンコーディングで保存されていることを確認して、インポート中の無効な文字の問題を防いでください。
アップロード前に、空の行または不要なスペースをチェックして、これらがインポートに干渉しないようにしてください。簡単なレビューで時間を節約し、潜在的なエラーを回避できます。
エンコーディングの問題でCSVインポートが失敗した場合はどうすればよいですか?
エンコーディングの問題によってCSVインポートが機能していない場合は、ファイルの文字エンコーディングを確認することが最初のステップです。 UTF-8などのサポートされている形式に設定されていることを確認してください。サポートされていないエンコーディングまたは特殊文字は、インポート処理中にエラーが発生することがよくあります。
これを解決するには、テキストエディターまたはエンコーディング設定を調整できるスプレッドシートツールを使用してCSVファイルを開きます。次に、ファイルを再度保存またはエクスポートして、 UTF-8エンコーディングを選択していることを確認してください。この調整は通常、問題を修正し、支障なくインポートを進めることができます。
CSVファイルをインポートする場合、データセットが10,000レコードの制限を超えた場合はどうすればよいですか?
データセットに10,000件を超えるレコードが含まれている場合は、CSVファイルを小さなチャンク(各チャンクは10,000件未満)に分割してください。分割後、各ファイルを個別にアップロードしてください。この方法により、システムの制約が問題を引き起こすのを防ぎ、シームレスなデータインポートプロセスを確保できます。
大家向けトップ7アプリ | 2026年版

上位5つのMap APIエラーと修正
5つの最も一般的なGoogle Maps APIエラーの簡単な修正:キーがない/無効、参照先制限、APIが無効、課金、および位置情報

リアルタイムGoogle Sheetsシンク:ベストプラクティス
信頼性の高いリアルタイムGoogle Sheetsシンクの実践的なステップ:データを整理し、一意のIDを追加し、権限を設定し、更新レートを最適化し、監視

Adaloは本番環境に対応していますか?パフォーマンスベンチマーク、稼働時間データ、スケール制限
Adaloのアップタイム、速度、スケーリングの分析。本番環境アプリのベンチマーク、制限事項、実用的な修正。

プッシュ通知テスト: 一般的な問題と修正
未配信のプッシュ通知を修正: 認証情報、トークン、権限、ペイロード、およびネットワークの問題を特定し、プラットフォーム固有のテストに従う